The shift towards automation in the automotive sector is giving rise to a plethora of cooperative distributed applications characterized by Quality-of-Service (QoS) constraints on the underlying 5G communication and computing infrastructure. In turn, this has fostered efforts to estimate QoS conditions and pro-actively adjust the network and/or service configuration, especially in cases of expected QoS degradation. For instance, the 5G-Automotive Association (5G-AA) has already proposed a framework for mobile networks to deliver In-advance QoS Notifications (IQN) to applications, in the so-called context of Predictive QoS[1].
The estimation of upcoming QoS conditions heavily builds on the use of historical data so as to gain insights of future system behavior. In the case of Artificial Intelligence and Machine Learning (AI/ML) this corresponds to the training of a ML model with historical data, so as to later use it for inference, based on the current conditions. Training is typically characterized by the need for large volumes of data (and corresponding 5G bandwidth), the correspondingly high computation load and the typically loose latency requirements. In the context of Predictive QoS, multiple data sources can be envisioned, including the 5G mobile network, having the vehicle itself as the natural focal point of past QoS experience and contextual information.
Applying the well-established centralized ML practices, where data are collected to a central location (e.g., a data lake) for training purposes, followed by the dispatching of the trained ML model, immediately reveals a particularly challenging environment: (i) training data can be of high volume consuming non-negligible network resources for collection, and/or (ii) subject to privacy concerns such as vehicle trajectory, while (iii) the dynamics of mobility call for a continuous learning process able to adapt to evolving and short-term conditions. The advent of Distributed Machine Learning (DML), including Federated Learning (FL)[2] promises to address some of these challenges by realizing multi-node ML systems that bring the (un-)trained model to the data (and not the other way around) and hence (re-)train, collect and aggregate model instances in repetitive (a)synchronous steps (Figure 1).
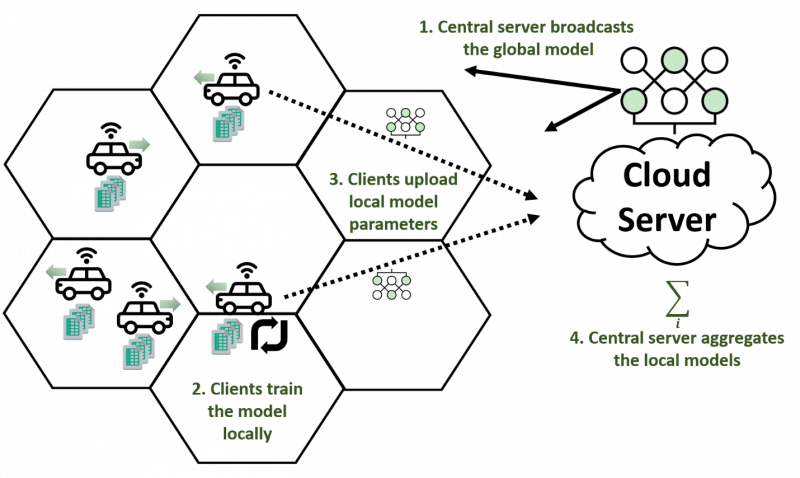
Figure 1: The DML-FL Framework: 1) A Model Aggregator within the central cloud server selects a subset of clients and dispatches the current global model to them, 2) The clients perform local model training, 3) The clients upload the local models back to the central server, and 4) The central server aggregates the local models.
However, adopting DML/FL in the context of 5G-enabled services/applications presents significant practical challenges when it comes to the overall Management and Orchestration (MANO) processes. Realizing a DML/FL scheme requires the inclusion of vehicle On-Board Units (OBUs) and Road-Side Units (RSUs) within the broader operational scope of MANO processes, which comes with challenges related to the integration of the virtualization and programmability capabilities on the corresponding devices, as well as the integration within the MANO fabric in the presence of intermittent connectivity/availability. Then, the distributed character of the training process poses the requirement for advanced DML/FL MANO primitives, reducing the complexity of processes such as client selection, overlay topology formation and placement e.g., hierarchical FL, model aggregation and/or data transfer (where applicable), from the application-level implementation, down to the simple consumption of corresponding interfaces and/or the definition of corresponding policies.
Focusing on the case of AI/ML-enabled Predictive QoS, 5G-IANA identifies and addresses these challenges with the purpose of providing generic MANO primitives and NetApp VNF support for the realization of DML/FL services/applications. Our work will build on active/passive network monitoring data produced in NOKIA 5G testbed in Ulm, Germany, which consists of 5 sites-with 3 radio cells each. The monitoring data will be used to feed a DML/FL-enabled Predictive QoS service, with the purpose of eventually delivering IQNs for consumption by other services. The spatio-temporal dimensioning of the overall service will be carefully assessed, also feeding to the corresponding service Life-cycle Management (LCM) operations e.g., selection of ML model and/or model aggregation server corresponding to spatio-temporal QoS maps of the region of interest (Figure 2).

Figure 2: DML/FL-enabled Predictive QoS with geo-fencing: Single-model (instance) approach, adopting a global ML
model for all areas (top), versus multi-model (instance) approach, adopting multiple ML-model(s) instances per area (bottom).
Authors: Konstantinos Katsaros, Nehal Baganal-Krishna, Amr Rizk, Eirini Liotou, George Drainakis, Markus Wimmer, Steffen Schulz.

[1] 5GAA Automotive Association, “Making 5G Proactive and Predictive for the Automotive Industry,” White Paper, Dec 2019.
[2] H. B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. Y. Arcas, “Communication-efficient learning of deep networks from decentralized data,” in Proc. 20th Int. Conf. Artif. Intell. Statist., 2017, pp. 1273–1282